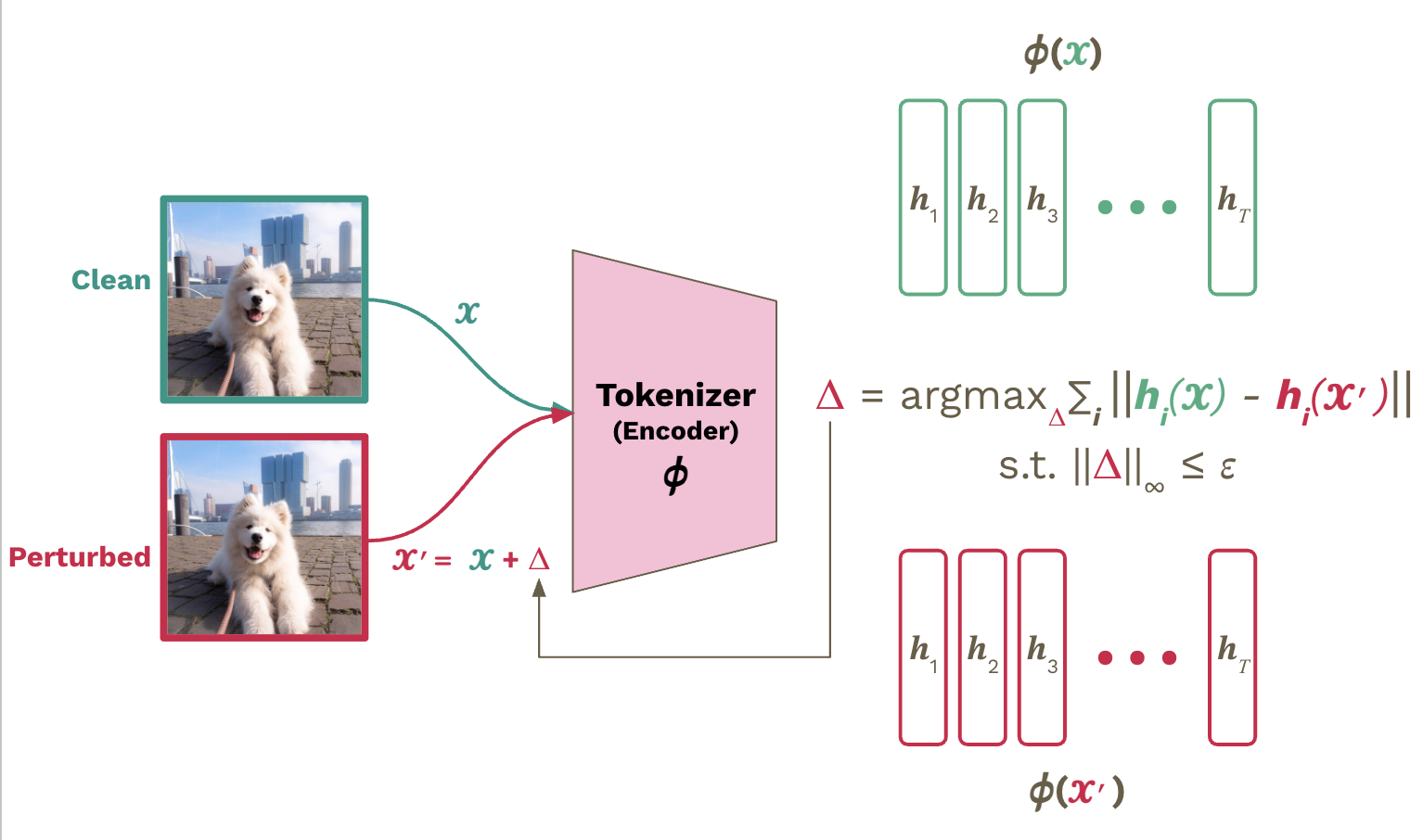
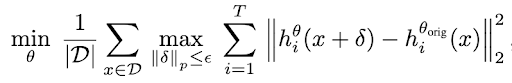
Main results
Robust tokenizers → Robust Embedding Models. We evaluate robustness after swapping the original tokenizer encoder with our unsupervised adversarially fine-tuned version, while keeping the downstream model frozen. For FuseLIP (TiTok-based), robust tokenizers substantially increase adversarial robustness on both classification (Imagenette, Caltech101) and multimodal retrieval (OI-Crop, OI-Pos), and the training radius provides explicit control over the robustness–accuracy trade-off. For UniTok, the same tokenizer-only fine-tuning also improves robustness against end-to-end attacks across Imagenette, Caltech101, and ImageNet.
Table 1. Evaluation of FuseLIP on image classification and multimodal retrieval.
| Tokenizer | Imagenette | Caltech101 | OI-Crop | OI-Pos | Average | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| clean | 2/255 | 4/255 | clean | 2/255 | 4/255 | clean | 2/255 | 4/255 | clean | 2/255 | 4/255 | clean | 2/255 | 4/255 | |
| clean | 93.6 | 2.6 | 0.0 | 74.4 | 0.6 | 0.0 | 71.8 | 7.4 | 0.8 | 69.2 | 5.4 | 1.4 | 77.3 | 4.0 | 0.6 |
| AT4/255 | 91.8 | 63.6 | 36.6 | 73.0 | 48.2 | 20.8 | 66.2 | 50.6 | 26.0 | 67.2 | 46.0 | 24.6 | 74.6 | 52.1 | 27.0 |
| AT8/255 | 89.6 | 69.0 | 48.8 | 72.4 | 51.6 | 32.8 | 62.0 | 48.8 | 35.8 | 64.8 | 51.2 | 35.6 | 72.2 | 55.2 | 38.3 |
| AT12/255 | 87.0 | 71.4 | 51.0 | 67.6 | 51.2 | 36.8 | 56.2 | 49.0 | 36.8 | 61.6 | 49.6 | 35.2 | 68.1 | 55.3 | 40.0 |
| AT16/255 | 83.4 | 66.6 | 50.0 | 61.2 | 47.6 | 37.4 | 50.0 | 47.2 | 35.8 | 59.4 | 48.8 | 39.2 | 63.5 | 52.6 | 40.6 |
Table 2. Evaluation of UniTok on image classification.
| Tokenizer | Imagenette | Caltech101 | ImageNet | Average | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| clean | 2/255 | 4/255 | clean | 2/255 | 4/255 | clean | 2/255 | 4/255 | clean | 2/255 | 4/255 | |
| clean | 99.2 | 0.0 | 0.0 | 85.7 | 0.0 | 0.0 | 67.3 | 0.0 | 0.0 | 84.1 | 0.0 | 0.0 |
| AT4/255 | 99.2 | 92.1 | 75.0 | 81.2 | 56.9 | 22.4 | 66.9 | 31.9 | 10.5 | 82.4 | 60.3 | 36.0 |
| AT8/255 | 97.8 | 91.5 | 82.7 | 77.4 | 63.5 | 43.9 | 58.3 | 40.3 | 23.6 | 77.8 | 65.1 | 50.1 |
| AT12/255 | 95.6 | 88.7 | 81.4 | 72.4 | 60.1 | 47.6 | 50.4 | 36.5 | 25.6 | 72.8 | 61.8 | 51.5 |
| AT16/255 | 92.7 | 86.3 | 79.6 | 65.3 | 57.5 | 44.6 | 42.3 | 32.1 | 23.6 | 66.7 | 58.7 | 49.3 |
Robust tokenizers → Robust Multimodal LLMs. We next study UniTok-MLLM by replacing only the image tokenizer with our robust UniTok variant. On VQA (VQAv2, OK-VQA, GQA), robust tokenizers yield large gains in adversarial accuracy under ℓ∞ attacks. On captioning, both unsupervised targeted (tokenizer-only) and supervised targeted (end-to-end) attacks can steer the original model toward the target caption, while the model with the robust tokenizer stays close to the correct description.
Targeted attacks on captioning
The examples below demonstrate targeted attacks: (i) an unsupervised targeted attack that matches the perturbed image’s tokenizer embeddings to a target image, and (ii) a supervised targeted end-to-end attack that optimizes toward a specific target caption. In both cases, the robust tokenizer prevents the model from switching to the target caption.
.png)
Unsupervised targeted attack
The attack minimizes the embedding distance between a perturbed input and a target image using only the tokenizer. The original UniTok-MLLM shifts toward the target caption, while the robust tokenizer preserves a correct, safe caption.
.png)
Supervised targeted attack
The end-to-end attack directly optimizes the image perturbation toward a chosen target caption. With the original UniTok tokenizer, the model can be forced to output the target caption; swapping in the robust tokenizer prevents this behavior and keeps captions aligned with the input image.